Now page update: poster art for shows and movies
It had been bothering me since adding my Trakt TV and Movie watched history to my /now page, that I was unable to display the relevant poster image. This is due to Trakt not exposing images in their API.
There must be a better way to go about this, and there is. Let’s combine two API calls, use eleventy-fetch, and lean on ChatGPT to bring it all together.
In the first iteration, I was using eleventy-fetch and feed-extractor to parse the atom feed that Trakt provides for movies and shows for tv.js and movies.js.
I saw that Cory had switched to using the Trakt API and used that as a starting point.
After a quick cruise through his repo, tv.js now looks like this:
const { extract } = require('@extractus/feed-extractor')
const { AssetCache } = require('@11ty/eleventy-fetch')
module.exports = async function () {
const TV_KEY = process.env.TRAKT_KEY
const url = 'https://api.trakt.tv/users/flamed/history/shows'
const res = EleventyFetch(url, {
duration: '1h',
type: 'json',
fetchOptions: {
headers: {
'Content-Type': 'application/json',
'trakt-api-version': 2,
'trakt-api-key': TV_KEY,
},
},
}).catch()
const shows = await res
return shows.splice(0, 6)
}And movies.js looks like this:
const EleventyFetch = require('@11ty/eleventy-fetch')
module.exports = async function () {
const MOVIE_KEY = process.env.TRAKT_API_KEY
const url = 'https://api.trakt.tv/users/flamed/history/movies'
const res = EleventyFetch(url, {
duration: '1h',
type: 'json',
fetchOptions: {
headers: {
'Content-Type': 'application/json',
'trakt-api-version': 2,
'trakt-api-key': MOVIE_KEY,
},
},
}).catch()
const movies = await res
return movies.splice(0, 4)
}Great, I could retrieve the same metadata but displaying it was still a boring unordered list with orange hyperlinks.
But where to get our images from? There are a few options to choose from, The Movie DB (TMDB), TheTVDB (TVDB), Fanart.tv, and Open Media Database (OMDB).
I made it as far as TMDB, signed up for an account and applied for an API key. Once I had my key I added it to my .env variables as TMDB_KEY.
Next was the hard part. Looking at the response received from the Trakt API, I could see that it returns ids.
An example of show.ids returned for the Shrinking.
"show": {
"title": "Shrinking",
"year": 2023,
"ids": {
"trakt": 189764,
"slug": "shrinking",
"tvdb": 411364,
"imdb": "tt15677150",
"tmdb": 136311,
"tvrage": null
}
}And an example of the movie.ids returned for Dinner In America.
"movie": {
"title": "Dinner in America",
"year": 2022,
"ids": {
"trakt": 488310,
"slug": "dinner-in-america-2022",
"imdb": "tt9058654",
"tmdb": 653664
}
}I knew that I wanted to take the value ids.tmdb from the Trakt API response and use that to construct a new API call to api.tmdb.org to retrieve the relevant poster art.
Not being able to do this myself was beyond my abilities, but I could use ChatGPT again to help me figure out what was needed.
To fetch the poster image file from api.themoviedb.org using the movie.ids.tmdb value, you can modify the method with the new API calls:
const EleventyFetch = require('@11ty/eleventy-fetch')
module.exports = async function () {
const MOVIE_KEY = process.env.TRAKT_API_KEY
const TMDB_KEY = process.env.TMDB_API_KEY
const url = 'https://api.trakt.tv/users/flamed/history/movies'
const res = await EleventyFetch(url, {
duration: '1h',
type: 'json',
fetchOptions: {
headers: {
'Content-Type': 'application/json',
'trakt-api-version': 2,
'trakt-api-key': MOVIE_KEY,
},
},
})
const movies = res.slice(0, 6)
for (const movie of movies) {
const tmdbId = movie.movie.ids.tmdb
const tmdbUrl = `https://api.themoviedb.org/3/movie/${tmdbId}?api_key=${TMDB_KEY}`
const tmdbRes = await EleventyFetch(tmdbUrl, {
duration: '1h',
type: 'json',
})
const posterPath = tmdbRes.poster_path
movie.posterUrl = `https://image.tmdb.org/t/p/w500${posterPath}`
}
return movies
}And to fetch the poster image file from api.themoviedb.org using the shows.ids.tmdb value, you can modify the method with the new API calls:
const EleventyFetch = require('@11ty/eleventy-fetch')
module.exports = async function () {
const TV_KEY = process.env.TRAKT_API_KEY
const TMDB_KEY = process.env.TMDB_API_KEY
const url = 'https://api.trakt.tv/users/flamed/history/shows'
const res = await EleventyFetch(url, {
duration: '1h',
type: 'json',
fetchOptions: {
headers: {
'Content-Type': 'application/json',
'trakt-api-version': 2,
'trakt-api-key': TV_KEY,
},
},
})
const shows = res.slice(0, 4)
for (const show of shows) {
const tmdbId = show.show.ids.tmdb
const tmdbUrl = `https://api.themoviedb.org/3/tv/${tmdbId}?api_key=${TMDB_KEY}`
const tmdbRes = await EleventyFetch(tmdbUrl, {
duration: '1h',
type: 'json',
})
const posterPath = tmdbRes.poster_path
show.posterUrl = `https://image.tmdb.org/t/p/w500${posterPath}`
}
return shows
}The method now fetches the metadata from the two APIs to get the overall metadata needed. Eleventy-fetch caches the data for us to use.
An HTTP request is made to the Trakt API to get a list of TV shows or movies. It specifies that it expects a JSON response and sets some request headers, including the API key.
The response from the Trakt API is stored in the res variable, selects the first four shows or movies from the response, and stores them in the shows variable.
Then it loops through each show or movie and makes another HTTP request to the TMDB API for additional details.
The response from the TMDB API is stored in the tmdbRes variable, extracts the poster path from the response, and constructs a complete URL for the image.
The constructed poster URL is then added to each show by assigning it to the posterUrl property.
Finally, it returns the modified array containing the first four shows or movies with their respective poster URLs.
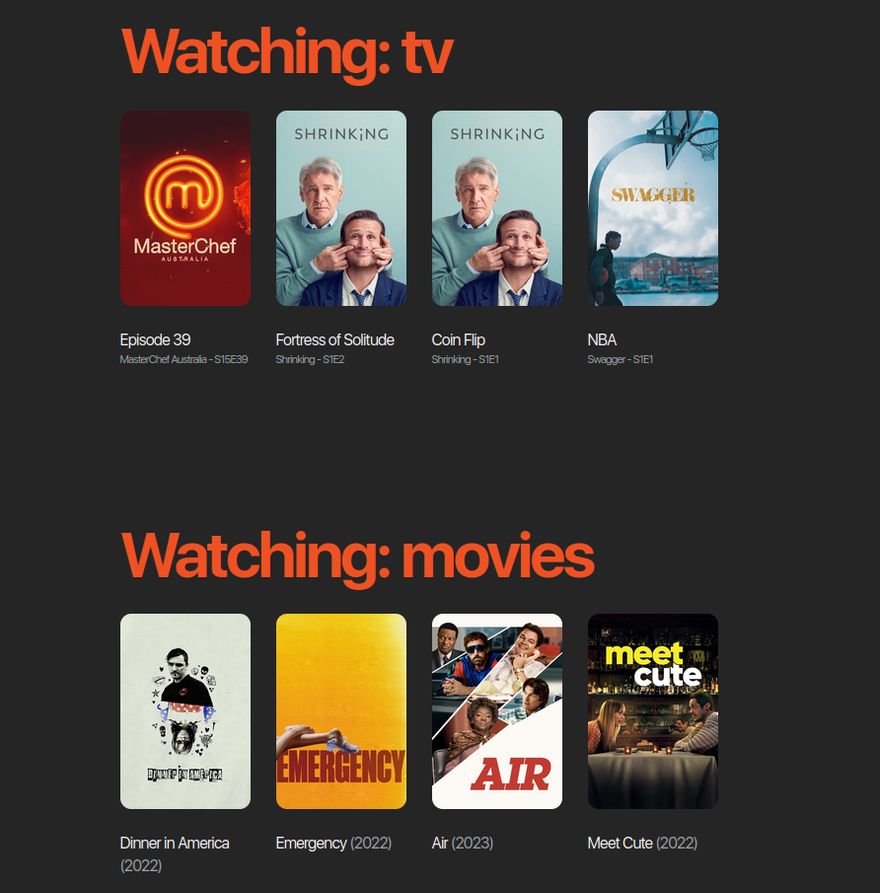
I can use show.posterUrl to display the poster image in my Nunjucks loop.
<article class="region">
<div class="wrapper flow">
<h2>Watching: tv</h2>
<div class="grid" style="--grid-min-item-size: 10rem">
{% for show in tv %}
<div class="flow">
<a href="https://trakt.tv/shows/{{ show.show.ids.slug }}/seasons/{{ show.episode.season }}/episodes/{{ show.episode.number }}" title="{{ show.show.title | escape }}">
<img src="{{ show.posterUrl }}" alt="{{ show.show.title }}"/>
</a>
<div class="show-meta">
<p class="show-episode-title">{{ show.episode.title }}</p>
<p class="show-title">{{ show.show.title }} - S{{ show.episode.season }}E{{ show.episode.number }}</p>
</div>
</div>
{% endfor %}
</div>
</div>
</article>
<article class="region">
<div class="wrapper flow">
<h2>Watching: movies</h2>
<div class="grid" style="--grid-min-item-size: 10rem">
{% for movie in movies %}
<div class="flow">
<a href="https://trakt.tv/movies/{{ movie.movie.ids.slug }}" title="{{ movie.movie.title | escape }}">
<img src="{{ movie.posterUrl }}" alt="{{ movie.movie.title }}"/>
</a>
<div class="movie-meta">
<p class="movie-title">{{ movie.movie.title }}
<span class="movie-date">({{ movie.movie.year }})</span></p>
</div>
</div>
{% endfor %}
</div>
</div>
</article>The result is a much nicer looking /now page.
I hope that this post has helped explain how I achieved this and that you are okay with that I used ChatGPT to help me accomplish it. Please look through and contact me if I need to correct anything. I’m always looking forward to improving my website overall.
